Human beings have two, not one,
ears at about equal height on both sides of the head. This
well-known fact is the basis of many of the outstanding features
of human auditory perception. Identifying faint signals in a
noisy environment, comprehending a specific talker in a group of
people all speaking at the same time, enjoying the
"acoustics" of a concert hall, and perceiving
"stereo" with our hi-fi system at home, would hardly be
possible with only one ear. In their effort to understand and to
take advantage of the basic principles of human binaural hearing,
engineers have done the groundwork for a new branch of technology
- now known as Binaural Technology. Binaural Technology is
able to offer a great number of applications capable of having
noticeable impact on society. One of these applications is the
representation of the auditory sensory domain in so-called
Virtual-Reality systems. To this end, physiologically-adequate
treatment of the prominent sensory modalities, including the
auditory one, is mandatory.
Technically speaking, auditory representation in VR systems is implemented by means of a sound system. However, in contrast to conventional sound systems, the auditory representation is non-stationary and interactive, i.e., among other things, dependent on listeners' actions. This implies, for the auditory representation, that very complex, physiologically-adequate sound signals have to be delivered to the auditory systems of the listeners, namely to their eardrums.
One possible technical way to accomplish this is via transducers positioned at the entrances to the ear canals (headphones). Headphones are fixed to the head and thus move simultaneously with it. Consequently, head and body movements do not modify the coupling between transducers and ear canals (so-called head-related approach to auditory representation) - in contrast to the case where the transducers, e.g. loudspeakers, are positioned away from the head and where the head and body can move in proportion to the sound sources (room-related approach). In any real acoustical situation the transmission paths from the sources to the ear-drums will vary as a result of the listeners' movements in relation to the sound sources- the actual variation being dependent on the directional characteristics of both the sound sources and the external ears (skull, pinna, torso) and on the reflections and reverberation present.
Virtual-reality systems must take account of all these specific variations. Only if this task is performed with sufficient sophistication will the listeners accept their auditory percepts as real - and develop the required sense of presence and immersion.
1. Auditory simulation for achieving a full sense of presence
2. Binaural technology in virtual auditory environments
3. Architecture of an auditory VR system
As the title of a well-known journal that deals with virtual environments is 'Presence', the concept of presence is central to research in this field. Definitions of presence have been done in a different number of ways, all these definitions include the feeling of 'being in the environment'. In the following paragraphs it will be summarised why the auditory stimulation has a great importance to reach the feeling of being in a virtual environment.
Sudden deafness
Outgoing from a report, in which Ramsdell (1978) discusses the psychological experience of hearing loss, Gilkey and Weisenberger (1995) describe the implications of sudden deafness on a number of patients. This deafness led to the description of the world as being 'dead', lacking movement, and by the use of terms of 'connected', 'part of' and 'coupling' the psychological effect that hearing has on the relationship between the observer and the environment was outlined. Ramsdell's interviews led him to divide the auditory information into three different levels: the social level, the warning level and the primitive level.
The level of information typically thought of when considering auditory functioning is the social level; comprehending language, listening to music, etc. This social or symbolic level is the venue for communication with other persons. Sounds interpreted on the second level, the warning level are for example the ringing of a telephone, the wail of a siren, etc.
On the third level, the primitive level sounds serve as neither warning nor symbol. They serve as auditory background sounds which surround us in our everyday life. These sounds can be caused by interaction with objects (e.g. writing on a keyboard, footsteps) or can consist of incidental sounds by objects in the environment (e.g. ticking of a clock). Ramsdell describes that these sounds maintain our feeling of being a part of a living world. He comes to the conclusion that the loss of sound on the primitive level is the major cause for the feelings of depression and loss reported by deaf patients.
The loss of the primitive level of hearing can be recognised
as having a significant impact on the sense of presence for
suddenly deafened persons. A straightforward approach is to
analyse an incomplete or non-existing representation of the
auditory background within a virtual environment.
Presence in Virtual Environments
In most virtual reality applications the visual feedback is considered to be the most important component. Often the effort on equipment for the visual system is by factor 10 or even by factor 100 higher than for the auditory system. That makes it obvious that the auditory feedback plays a minor role in current implementations of virtual environments. As described is the influence of the auditory stimulation for the presence in a virtual world often underestimated though it is more critical than the visual stimulation in the sense of presence. On the one hand, when a person closes one's eyes it does not significantly alter the sense of presence, the absence of the visual stimulation is experienced routinely in our everyday live when closing the eyes. One the other hand, the absence of the auditory stimulation cannot be considered as a normal situation because, as Ramsdell points out, humans have no 'earlids'. As the feeling of presence cannot be reached by one sense it is a straightforward approach to couple different senses to reach an optimal feeling of presence within a virtual reality. That aim can be achieved by the use of multimodal virtual reality systems. Within the project SCATIS (ESPRIT basic research project #6358), for example, an auditory-tactile virtual environment system was built up in order to create presence in a virtual world with more than one sense and to carry out research in the field of multi-modal psychophysics. Further research in this field is needed to gain more information about the combination of stimulation of different senses in order to reach a feeling of presence. Concerning the auditory stimulation research is needed to specify the importance of the auditory background compared to other forms of auditory stimulation as well as it has to be specified how exact and detailed the auditory background has to be modelled in order to achieve a convincing auditory experience.
The human auditory system consists at one end of two ears. Each ear scans the variation in time of the sound pressure at two different positions in the environment. Spatial hearing is performed by evaluating monaural clues, which are the same for both ears, as well as binaural ones, which differ between the two eardrum signals. In general, the distance between a sound source and the two ears is different for sound sources outside the median plane. This is one reason for interaural time, phase and level differences that can be evaluated by the auditory system for directivity perception. These interaural clues are mainly used for azimuth perception (left or right), which is usually quite accurate (up to 1 degree). Exclusively interaural levels and time differences do not allow univocal spatial perceptions. Monaural cues are mainly used for perceiving elevation. These are amplifications and attenuations in the so-called directional (frequency) bands. Particularly the presence of the external ear (consisting of head, torso, shoulders and pinnae) has decisive impact on the eardrum signals. Diffraction effects depending on the direction of incidence occur when sound waves impinge on the human's head.
Binaural technology is used in virtual auditory environments to perform spatial hearing. The basics of this technology will be described in this chapter.
Binaural-Technology Basics (Blauert&Lehnert, 1994)
At this point it makes sense to begin the technological discussion with the earliest, but still a very important category of application in Binaural Technology, namely, "binaural recording and authentic auditory reproduction." Authentic auditory reproduction is achieved when listeners hear exactly the same in a reproduction situation as they would hear in an original sound field, the latter existing at a different time and/or location. As a working hypothesis, Binaural Technology begins with the assumption that listeners hear the same in a reproduction situation as in an original sound field when the signals at the two ear-drums are exactly the same during reproduction as in the original field. Technologically speaking, this goal is achieved by means of so-called artificial heads which are replicas of natural heads in terms of acoustics, i.e. they develop two self-adjusting ear filters like natural heads. Applications based on authentic reproduction exploit the capability of Binaural Technology to archive the sound field in a perceptually authentic way, and to make it available for listening at will, e.g., in entertainment, education, instruction, scientific research, documentation, surveillance, and telemonitoring. It should be noted here that binaural recordings can be compared in direct sequence (e.g., by A/B comparison), which is often impossible in the original sound situations.
Since the sound-pressure signals at the two ear-drums are the physiologically-adequate input to the auditory system, they are furthermore considered to be the basis for auditory-adequate measurement and evaluation, both in a physical and/or auditory way. Consequently, there is a further category of applications, namely "binaural measurement and evaluation" In physical binaural measurement physically based procedures are used, whereas in the auditory cases human listeners serve as measuring and evaluating instruments. Current applications of binaural measurement and evaluation can be found in areas such as noise control, acoustic-environment design, sound-quality assessment (for example, in speech-technology, architectural acoustics and product-sound design,) and in specific measurements on telephone systems, headphones, personal hearing protectors, and hearing aids. For some applications scaled-up or scaled-down artificial heads are in use, for instance, for evaluating architectural scale models.
Since artificial heads are basically just a specific way of implementing a set of linear filters, one may think of other ways of developing such filters, e.g., electronically. For many applications this adds additional degrees of freedom, as electronic filters can be controlled at will over a wide range of transfer characteristics. This idea leads to yet another category of applications: "binaural simulation and displays." There are many current applications in binaural simulation and displays, and their number will certainly further increase in the future. The following list provides examples: binaural mixing, binaural room simulation, advanced sound effects (for example, for computer games), provision of auditory spatial-orientation cues (e.g., in the cockpit or for the blind), auditory display of complex data, and auditory representation in teleconference, telepresence and teleoperator systems.
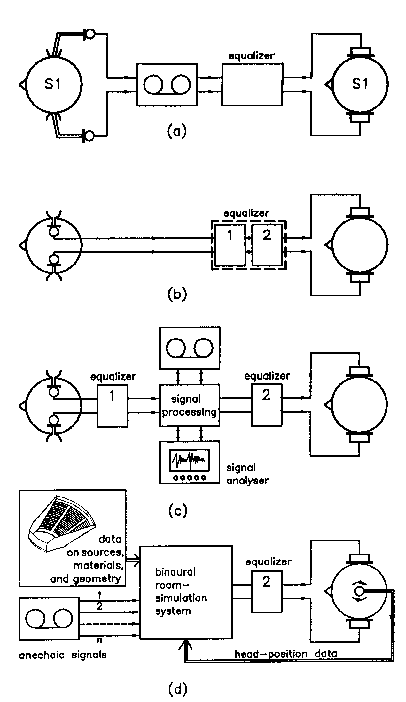
Fig.1, showing Binaural-Technology equipment in an order of increasing complexity, is meant to illustrate some of the ideas discussed above. The most basic equipment is obviously the one shown in panel (a). The signals at the two ears of a subject are picked up by (probe) microphones in a subject's ear canal, then recorded, and later played back to the same subject after appropriate equalization. Equalization is necessary to correct linear distortions, induced by the microphones, the recorder and the headphones, so that the signals in the subject's ear canals during the playback correspond exactly to those in the pick-up situation. Equipment of this kind is adequate for personalized binaural recordings. Since a subject's own ears are used for the recording, maximum authenticity can be achieved.
Artificial heads (panel b) have practical advantages over real heads for most applications; for one thing, they allow auditory real-time monitoring of a different location. One has to realize, however, that artificial heads are usually cast or designed from a typical or representative subject. Their directional characteristics will thus, in general, deviate from those of an individual listener. This fact can lead to a significant decrease in perceptual authenticity. For example, errors such as sound coloration or front-back confusion may appear. Individual adjustment is only partly possible, namely, by specifically equalizing the headphones for each subject. To this end, the equalizer may be split into two components, a head equalizer (1) and a headphone equalizer (2). The interface between the two allows some freedom of choice. Typically, it is defined in such a way that the artificial head features a flat frequency response either for frontal sound incidence (free-field correction) or in a diffuse sound field (diffuse-field correction). The headphones must be equalized accordingly. It is clear that individual adjustment of the complete system, beyond a specific direction of sound incidence, is impossible in principle, unless the directional characteristics of the artificial head and the listener's head happen to be identical.
Panel (c) depicts the set-up for applications where the signals to the two ears of the listener are to be measured, evaluated and/or manipulated. Signal-processing devices are provided to work on the recorded signals. Although real-time processing is not necessary for many applications, real-time play back is mandatory. The modified and/or unmodified signals can be monitored either by a signal analyzer or by binaural listening. The most complex equipment in this context is represented in panel (d). Here the input signals no longer stem from a listener's ears or from an artificial head, but have been recorded or even generated without the participation of ears or ear replicas. For instance, anechoic recordings via conventional studio microphones may be used. The linear distortions which human ears superimpose on the impinging sound waves, depending on their direction of incidence and wave-front curvature, are generated electronically via a so-called ear-filter bank (electronic head). To be able to assign the adequate head transfer function to each incoming signal component, the system needs data about the geometry of the sound field. In a typical application, e.g. architectural-acoustics planning, the system contains a sound-field simulation based on the data of the room geometry, the absorption features of the materials implied, and the positions of the sound sources and their directional characteristics. The output of the sound-field modelling is fed into the electronic head, thus producing so-called binaural impulse responses. Subsequent convolution of these impulse responses with anechoic signals generates binaural signals like the ones the subject would observe in a corresponding real room. The complete method is often referred to as binaural room simulation.
To give subjects the impression of being immersed in a sound field, it is important that a sense of spatial constancy is provided perceptually. In other words, when the subjects move their heads around, the perceived auditory world should nevertheless maintain its spatial position. To this end, the simulation system needs to know the head position in order to be able to control the binaural impulse responses adequately. Head position sensors (trackers) have therefore to be provided. It is at this point that interactivity has to be introduced into the system - and the transition to the kinds of system which are referred to as Virtual-Reality systems, takes place.
Binaural room simulation (Strauss&Blauert, 1995)
As has already been mentioned above, the two ears represent the input ports of the human auditory system. Therefore, to place a subject into a virtual auditory environment it is necessary to present the signals at both eardrums as being similar to the signals that would be present in a corresponding real environment. Obviously it is easiest to use headphones as an auditory display, because the binaural signals to be presented to the eardrums can be given directly to the headphone´s transducer terminals after an adequate equalisation of the headphones transfer function. Disturbing crosstalk between the two audio channels cannot occur.
The tasks in order to create a virtual auditory environment are as follows:
Auralizing a single sound source is comparatively easy. Given the position of the sound source and the subject's head, the distance and the direction of incidence can be calculated. Auralization is performed by convolving an anechoic sound signal with the corresponding head related impulse responses (HRIR) in real-time. The overall gain is adjusted according to the distance between the sound source and listener. Absorption of sound in the air over long distances can either be modelled by appropriate overall gain reduction or by frequency dependent gain reduction. Complex directivity characteristics of the sound source can also be implemented using appropriate prefiltering as a function of frequency and direction of emittance. Monopole synthesis and spherical harmonic synthesis have been successfully examined for the purpose of efficiently storing directivity data (Giron, 1993).
The model as yet does not take into account any impact of the surrounding environment upon the listener's auditory perception. Many conclusions can be drawn alone from the auditory perception on the environment. For example the interior of a church sounds completely different compared to a small living room, independent on the type of signal that the room is excited by. The total absence of reflections, for example in an anechoic chamber, can even be an unpleasant sensation for people who are not used to the absent auditorily perceivable environment. Furthermore, it is believed that reflection patterns are important clues to proper distance perception. The impact of the reflective environments onto the perceived sound can be modelled with the help of binaural room simulation algorithms (Lehnert, 1992). These algorithms make use of geometric acoustics: Provided that the wavelength of the sound is short, compared to the linear geometric dimensions of the surfaces in the room, and long, compared to the roughness and bendings of these surfaces, the sound waves are propagated almost in straight lines in form of sound rays that are reflected according to the optical reflection law on surfaces. Though the assumption above is not true for all perceivable wavelengths of sound, it has been shown (Pompetzki, 1993) that reasonable results can be achieved using geometric acoustics. Of course, wave effects like diffraction and diffuse reflections cannot be exactly modelled using geometric acoustics at first hand. This would require the acoustic wave equation for the sound pressure to be numerically solved with respect to complex boundary conditions given by the reflective surfaces. Because a great deal of computational effort is needed, especially for high frequencies, this method is currently not suitable for real-time applications.
Two appropriate methods are presently known for the modelling:
the mirror-image method (Allen & Berkley 1979, Borish 1984)
and different kinds of ray-tracing (Krokstadt et al 1968).
Although ray-tracing is initially not suitable for the
computation of secondary sound sources, it has been shown
(Lehnert 1993) that the results of a ray-tracing procedure can be
post-processed so that the results are identical with that of the
image method.
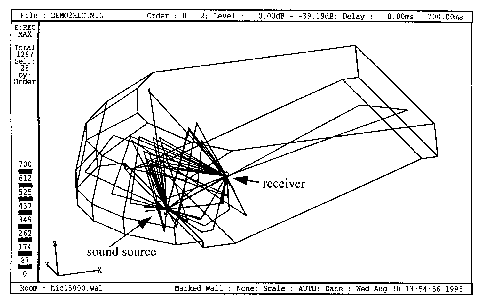
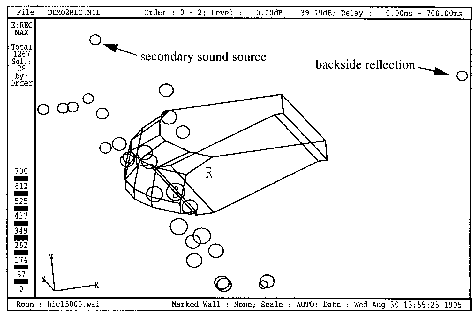
According to the so called mirror image model (Allen, Berkley, 1979), primary sound sources have to be mirrored on all geometric surfaces of the environment, to obtain virtual secondary sound sources. The algorithm can be applied recursively for these secondary sources to obtain secondary sound sources of a higher order. However, not all of the secondary sound sources found with this procedure are acoustically relevant, because the surfaces are not generally extended infinitely. Therefore most of the calculated reflections lie outside the boundaries of the corresponding walls or the sound path is blocked by other walls. Much effort in terms of calculation power is necessary to filter out the relevant sound sources by performing visibility investigations. An alternative method for finding secondary sound sources is the ray-tracing algorithm. It is comparable to corresponding rendering algorithms applied in the field of computer graphics. Rays are sent out from each sound source in different directions and their propagation in the room is traced. Rays hitting surfaces of the environment are reflected according to the reflection law. Diffuse reflections can be modelled by adding random components to the reflection angle. All rays that hit a detection sphere around the receiver are acoustically relevant for the simulation. The positions of secondary sound sources can easily be found by backtracking these rays. However, when putting the rays-tracing algorithm into practice, because of the finite number of rays and the infinite detection sphere around the receiver, missing or multiple detections have to be considered. The role of the sound source and the receiver can also be reversed. This requires less effort if more than one sound source is present. If, in theory, calculation time were unlimited, both algorithms would find the same distribution of virtual sound sources. The ray-tracing algorithm is usually more efficient for finding high order reflections while the mirror image model is preferable when only low order reflections are required. A sequence of indices is assigned to each secondary sound source specifying the walls where the sound has been reflected on its way to the listener. Optionally, reflection angles for each reflection can be stored for simulating angle dependent reflection characteristics. The complete characteristics of the environment as a result of this sound field modelling process can therefore be represented by a spatial map of secondary sound sources (Lehnert and Blauert 1989) in a reflection free space.
A detailed description of the algorithms, their variations, their compatibility, and their performance with respect to room acoustical problems can be found in Lehnert & Blauert (1992a), Lehnert (1993).
A relatively large amount of literature is available on the application of computer models to room acoustical problems. A good overview on the current state-of-the-art and a representative collection of contemporary papers may be found in two special issues of Applied Acoustics. These are Vol. 36 Nos. 3 and 4 (1992): "Special issue on Auditory Virtual Environment and Telepresence" and Vol. 38 (1993) Nos. 2-4: "Special Issue on Computer Modelling and Auralization of Sound Fields in Rooms". Each sound source can be auralized with the help of the head related transfer functions (HRTFs) as described in an earlier section. Directivity characteristics of the source and wall reflection characteristics can be modelled using prefilters. Wall reflectance data can be found in literature or be obtained from direct measurements usually carried out in reverberation chambers. The result of this primary filter process is a binaural impulse response for each virtual sound source. The binaural room impulse response is obtained by summing up all the binaural impulse responses from each virtual sound source. It can be interpreted as the two sound pressure signals at the eardrums that would be measured if the sound source emitted an ideal impulse. The room impulse response describes completely the transfer characteristics of the environment between a sound source and the listener. For auralization purposes, anechoic audio signals have to be convolved with the binaural room impulse response. This convolution requires an enormous amount of calculation power that cannot reasonably be performed in real-time, so simplifications are necessary. Exact auralization can be restricted to first and second order reflections because reflections of a higher order are hard to be perceived separately.
These reflections can be modelled with conventional
reverberation algorithms which only consider statistical
properties of the late reflections. Direct sound and first/second
order reflections can be auralized in real-time by distributing
the corresponding virtual sound sources to several digital signal
processors (DSPs) connected in a network. The system for
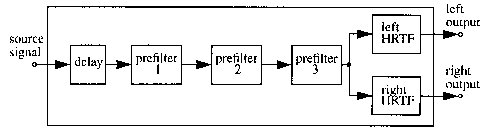
auralizing one virtual sound source, shown in figure 4, is called
an auralization unit. The delay is proportional to the distance
between the source and the receiver and represents the time that
the sound needs to reach the listener. The three prefilters used
in SCATIS allow up to second order sound sources with directivity
characteristics or even up to third order reflections without
directivity characteristics of the sound source to be simulated.
All the auralization units (32 in SCATIS) can work in parallel on
several processors and their results have to be added together to
obtain the complete auralized signal.
General system
architecture (Strauss&Blauert, 1995)
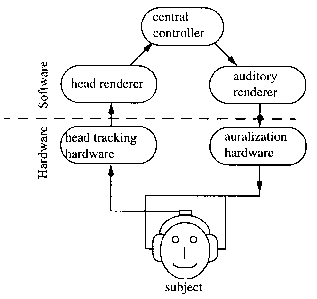
Figure 5 shows the general structure of an auditory virtual
environment system. Its afferent pathway can easily be integrated
into a complete virtual environment system with parallel afferent
pathways, for example for visual or tactile rendering.
The head position and orientation is frequently measured by head tracking hardware, usually based on modulated electromagnetic fields. Measured position and orientation data is passed on to the head renderer process that is used to buffer the data for immediate access by the central controller. Simple transformations, like offset additions, may be applied to the data in the head renderer process.
The central controller implements the protocol dynamics of a
virtual environment application. It accepts events from all
efferent renderers, evaluates them and reacts by sending
appropriate events resulting from the evaluation to the afferent
renderers. For example in a multimodal application with an
integrated hand gesture renderer, the central controller could
advise the auditory renderer to move sound sources represented by
objects that can be grasped in the virtual world. Auditory
renderer and auralization hardware have already been described in
the previous section.
The following events are relevant to the sound-field model and have to be treated in a different manner (Blauert&Lehnert, 1994):
Since the sound field model can be assumed to be the most time consuming part, any kind of optimisation is desirable. The splitting of movement in translation and rotation is somewhat arbitrary since the head-position tracker device will always deliver all six degrees of freedom at once. Looking at the tracker data one will find that the head always does very small translations even if the subject tries not to move. It is certainly not reasonable to recalculate the sound field model for these small variations.
Two steps can be used to optimise the behaviour. Firstly, a
translation threshold value can be specified. Translations below
that threshold can simply be ignored. Secondly, an approximation
for small translations, as they might occur for a seated subject,
can be given: The positions of all the secondary sources are
determined by the position of the sound source and the geometry
of the reflecting surfaces. The dependency on the position of the
receiver is only indirect and is included in the so-called
visibility and obstruction tests. These tests do not influence
the position of the secondary sources but only determine whether
a given source is valid or not. For small translations it can be
assumed that the validity does not change and the secondary
sources will remain unchanged. Consequently, the translations can
be modelled by simply recalculating the delays and the directions
of incidence for the already given set of secondary sources. A
similar approximation is possible for small translations of the
sound source. Assuming that the visibility of the current set of
secondary sources is not influenced by the translations, the new
positions of the secondary sources can be calculated according to
the trajectory of the primary source, a procedure which is
relatively easy to perform. For larger translations these
approximations are no longer valid and a complete re-execution of
the sound field model is required. If recalculating the sound
field is so time consuming that the smoothness of the simulation
is severely disturbed, it might be useful to execute the model in
several frames. To this end, only a part of the sound field is
modelled during one frame and for the remaining part the
approximation method is used. Updates are performed as soon as
new results become available. Using this method the display frame
rate can be higher than the execution rate of the sound field
model. The resulting error is that position updates of
reflections are delayed by one or more frames. The perceptual
effects of these errors can be kept small by scheduling the
updates according to the perceptual relevance of a specified
sound field component.
Auditory rendering
(VETIR, 1995)
The task of an auditory renderer is to compute the spatial, temporal, and spectral properties of the sound field at the subject's position for a given virtual world model taking into account all physical parameters that influence the sound field in the physical reality. To this end, a sound field model needs to be established whose results can be auralized by the front end. A suitable form of describing these results is the spatial map of secondary sound sources (Lehnert & Blauert 1989). The sound field is modelled by a cloud of discrete sound sources that surrounds the listener in a free sound field. Recently, (Møller 1993) an attempt has been made to define a standard format for a description of the spatial map of secondary sound sources.
Most of the present sound-field-modelling systems are based on the methods of geometric acoustics. Two appropriate methods, the mirror-image method and ray-tracing have been described in an earlier chapter.
However, no attempt has been made up to now to apply these
complex models to non-trivial environments in real time systems.
Real-time development was first discussed by Lehnert (Lehnert
& Blauert 1991, Lehnert 1992b) where the following procedure
was proposed:
In contrast to the digital generation of reverberation which has a long history (e.g. Schroeder 1962), no experience with real-time sound field modelling is available. The key-problem of the application of detailed sound field models in virtual reality is, of course, the required computation time.
Both, ray-tracing and the image method, have been compared frequently concerning their efficiency (Hunt 1964, Stephenson 1988, Vorländer 1988). However, these results can not easily be applied to the current problem, since only the early reflections have to be considered. Also, a wide variety of ray-tracing dialects exists, and the papers listed above did not deal with dialects suitable for the calculation of secondary sources.
Since the application in VR is very time critical, both methods need to be compared with respect to their achievable frame rate and their real-time performance. To this end, benchmarks have been performed by RUB using existing programs on a Sun 10/30 workstation with 10 MFlops of computational power. The test scenario was a room of moderate complexity with 24 surfaces, where eight first-order and 19 second-order reflections occurred for the specific sender-receiver configuration. This virtual environment may be considered as similar to a typical acoustical scenario for VREPAR. The resulting computation times, Tr, for the ray tracing could be approximated by
Tr = N.o.100 ms, (1)
where N is the number of rays and o the maximum order up to which the rays are traced. For the mirror image method the computation time Tm can roughly be expressed as
Tm = 12(o-1) ms. (2)
If the reflections up to the second order are to be computed, the resulting rendering times are 12 ms for the image method and 60 ms for the ray-tracing method, where 300 rays were necessary to find all 8 reflections. However, if only 24 rays were traced, the resulting rendering time was less then 5 ms and still 16 out of 28 reflections were found. The results of these pilot experiments can be summarised as follows:
For the test scenario, the mirror image method showed better performance than the ray-tracing method. It is also more safe, since it will always find all geometrically correct sound paths whereas this can not be guaranteed by the ray-tracing method. It is also difficult to predict the required number of rays. The ray-tracing method, on the other hand, has the advantage that even for very small rendering times still reasonable results are produced. It can easily be adapted to a given rendering time by adjusting the number of rays. This is very difficult for the mirror image method, since the algorithm is inherently recursive.
Ray-tracing will yield better results in more complex environments, since the dependency of the rendering time on the number of walls is linear and not exponential as it is the case for the mirror image method. Recently, an extension of the ray-tracing algorithm has been developed, where the rendering time can be expected to be nearly independent of the number of walls. This extension facilitates the simulation of scenarios with nearly arbitrary high degrees of complexity. It should be noted that this extension needs a certain amount of pre-processing of the room geometry, which probably cannot be done in real time. There is considerable risk that this extension can only be applied to static scenarios which are scenarios where the geometrical arrangement of sound reflecting surfaces does not change.
As a conclusion, it seems difficult to give a clear preference
to one of the two methods. There will most probably be scenarios
where the mirror image method will be superior, and others where
the ray-tracing method offers better performance.
Please consult this chapter's references to get more information about these issues.
For any questions or requests, please contact auxo.psylab@auxologico.inet.it